*OLA#5Doc 15,16,17 décembre 2017 Python Algolittéraire avec An Mertens site web: http://192.168.99.35:8008/ mail an: an@constantvzw.org mail bachir: bachir@figureslibres.io
Sources: https://figureslibres.io/gogs/bachir/ola5doc
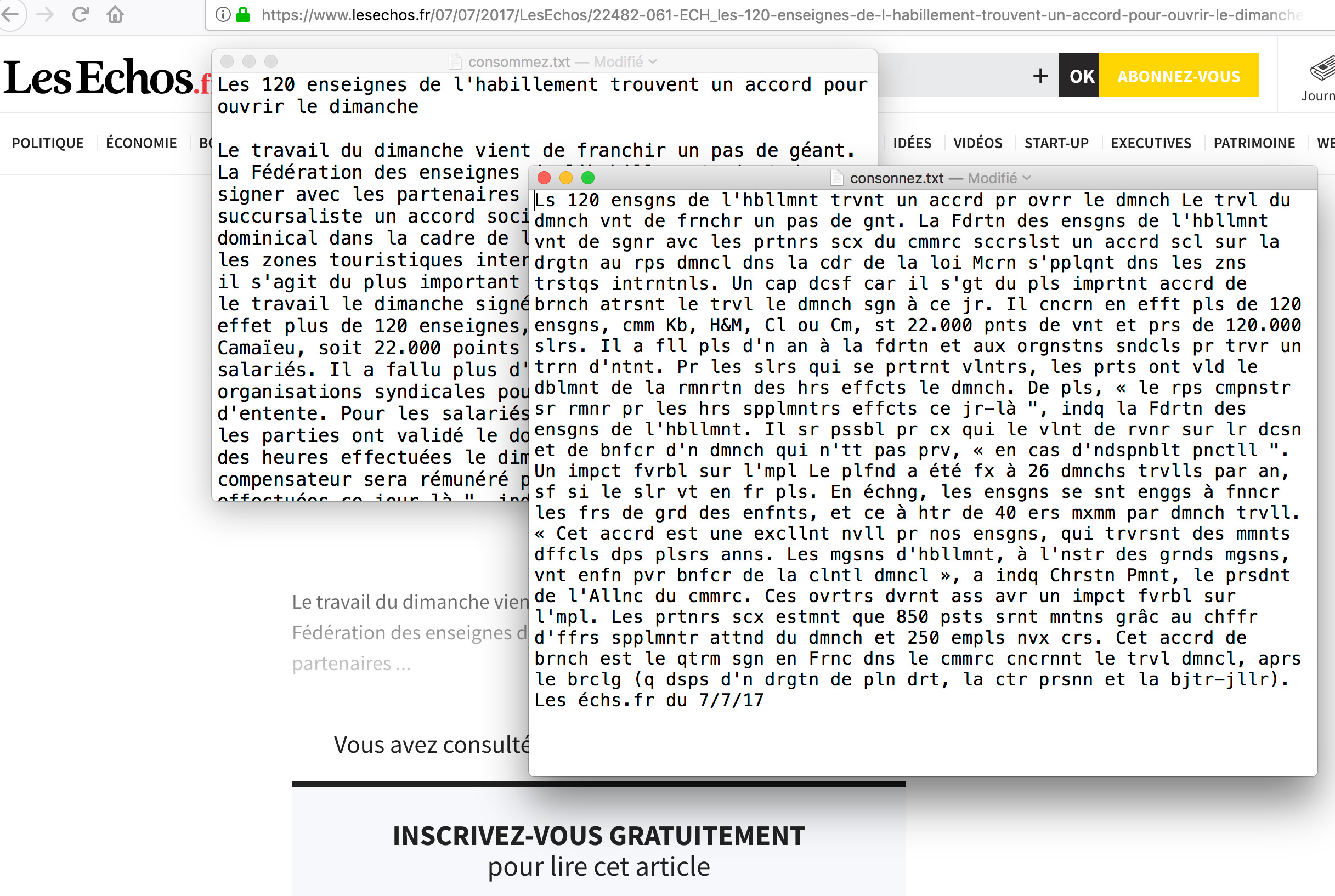
Porjet RNN : machine learning générer des textes à partir de l’étude de textes (ex : L’étude des ouvrages de Jules Vernes donne des textes qui ont un style d’écriture semblable à l’auteur). L’algo se base sur les probabilités. Montrer l’entrainement de la machine en proposant plusieurs étapes de construction.
We are sentiment thermometer programme qui mesure l’émotion d’une phrase
Python est langage créé par Guido Van Rossum en 1991
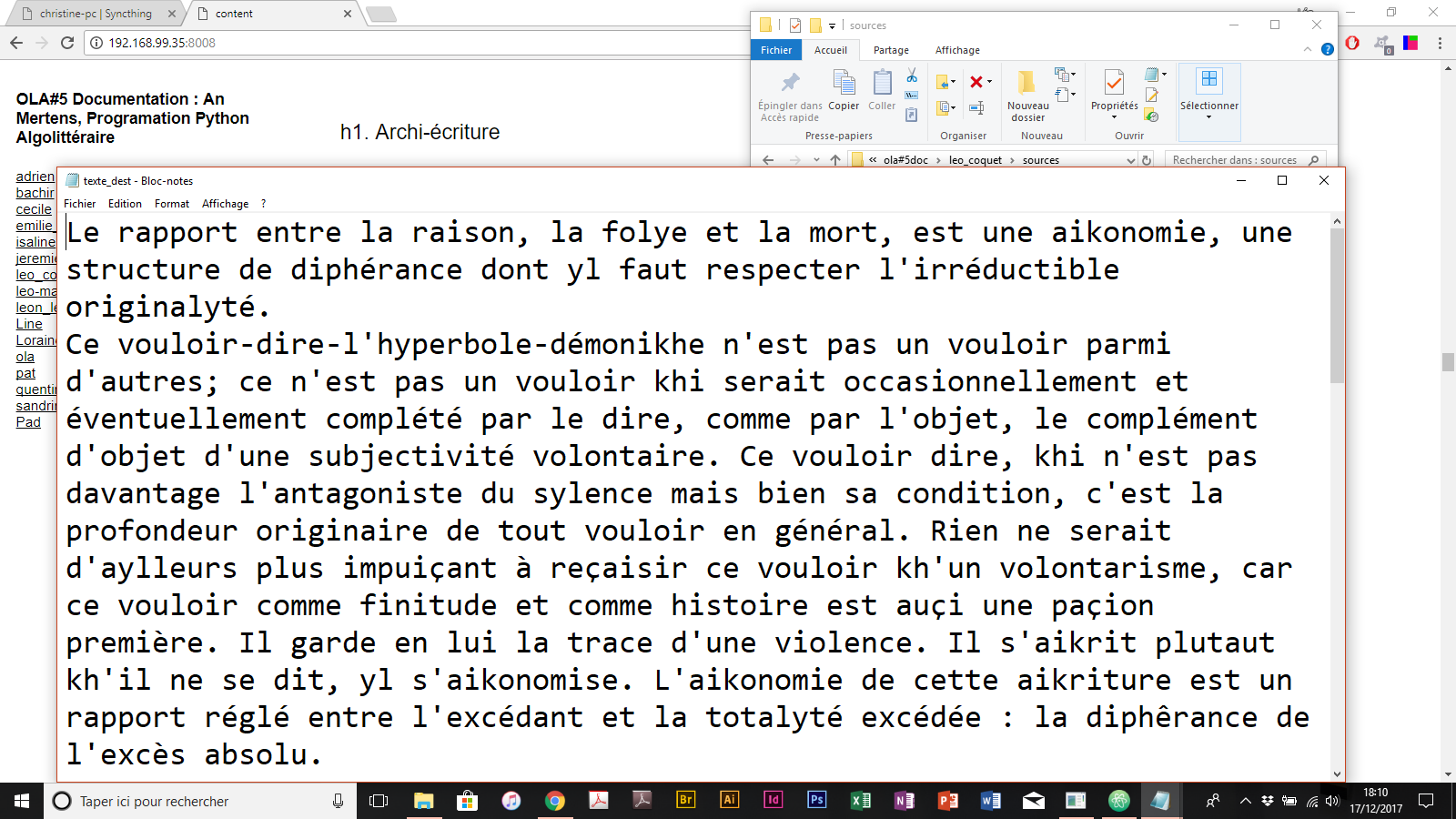
The Death of the Authors, 1941 édition générative avec python
Oulipo : L’Ouvroir de littérature potentielle, généralement désigné par son acronyme OuLiPo (ou Oulipo), est un groupe international de littéraires et de mathématiciens se définissant comme des « rats qui construisent eux-mêmes le labyrinthe dont ils se proposent de sorti. https://fr.wikipedia.org/wiki/Oulipo
*Liens discutés vendredi soir (n’hésitez pas à compléter/détailler/trier)
*Tour de table du début :
http://diccan.com/ https://prepostprint.org/ http://www.ppafeditions.fr/
*Présentation de An :
Constant (Association pour l’art et les médias) http://www.constantvzw.org/site/?lang=fr
Samedies (Femmes et logiciels libres) http://www.samedies.be/
Algolit (Groupe de travail sur l’algolittéraire) http://www.algolit.net/index.php/Main_Page
Anna K (Projet autour du travail de l’écrivaine Anna Kavan) http://kavan.land/
Paramoulipist (Expérimentations en i-littérature) http://www.paramoulipist.be/
RYBN (Collectif d’artistes) http://rybn.org/
Oulipo.net (Site de l’oulip) http://oulipo.net/
Quick sort with Hungarian folk dance (la vidéo youtube) https://www.youtube.com/watch?v=3San3uKKHgg
Projet Gutenberg (des textes) http://www.gutenberg.org/
*Atelier
Exercise d’écriture avec protocol (sans machine)
Python introduction
Python sur Windows - manuel: https://www.youtube.com/watch?v=HWxBtxPBCAc&list=PLrSOXFDHBtfHg8fWBd7sKPxEmahwyVBkC
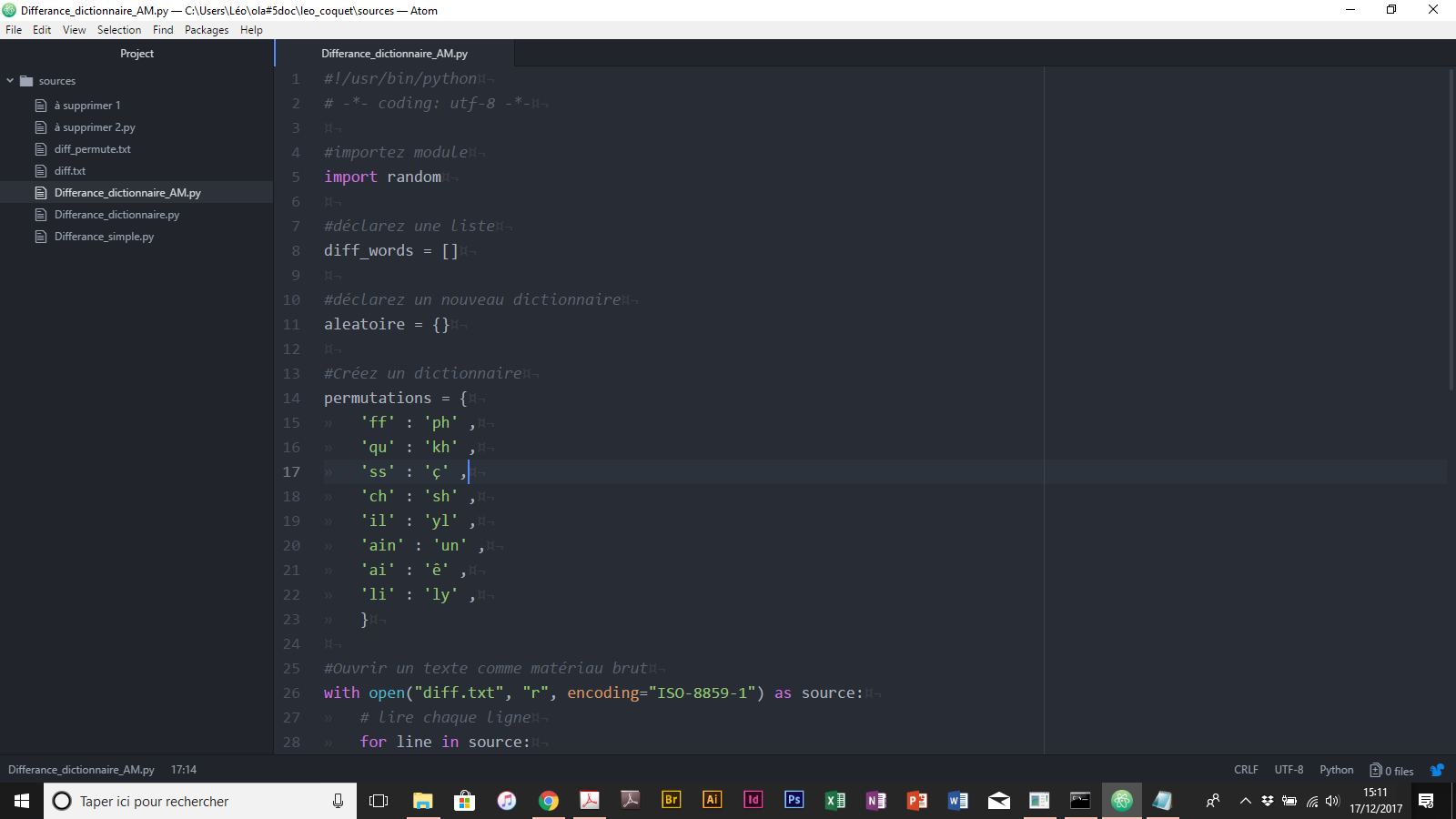
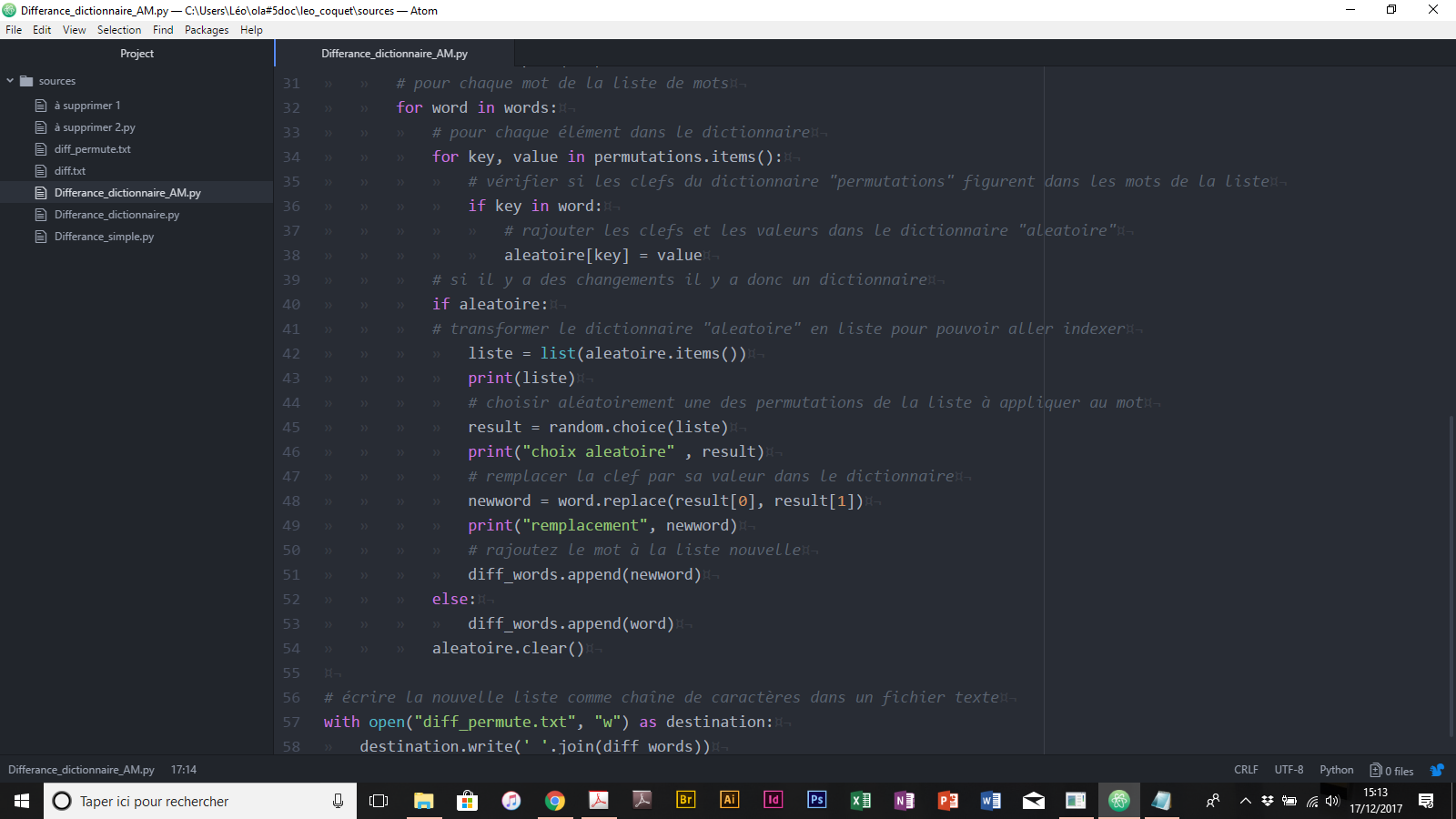
PYTHON
- open terminal Windows Terminal accès: http://smallbusiness.chron.com/open-terminal-session-windows-7-56627.html Windows Terminal commands: https://commandwindows.com/command3.htm
Pour Linux/Mac: lister les fichiers dans le dossier où tu es: $ ls changer de dossier: $ cd nom_du_dossier remonter un niveau $ cd ../
install atom / bracket
éventuellement PYTHON IDLE $ sudo apt install idle
$ idle this gives the same python shell
$ idle python_script.py this allows you to edit a script
dans un éditeur de code:
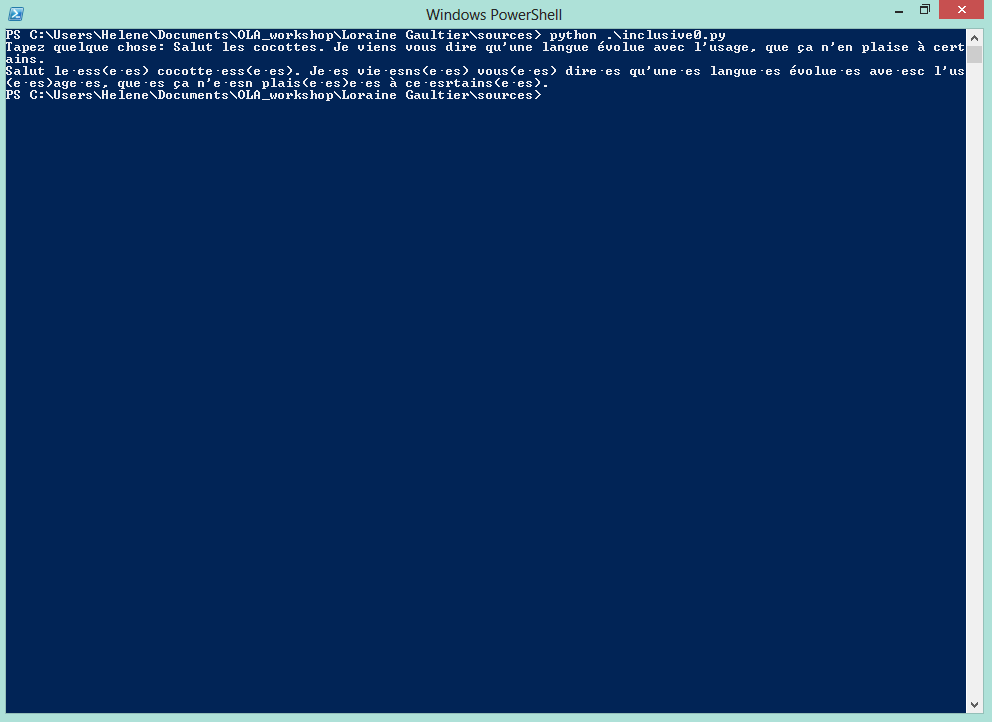
$ print(“o”+“l”+“a”)
$ letter1 = ‘o’ $ letter2 = ‘l’ $ letter3 = ‘a’ $ print(letter1,letter2,letter3) $ print(letter1+letter2+letter3)
sauver le script comme test.py $ python test.py
Eventuellement (p.ex. pour voir quelle version de Python que tu as par défaut): $ python $ print(“o”+“l”+“a”) Sortir de Python: $ quit()
Get scripts
Download zip from algolit: www.algolit.net/oulipo -> plutot téléchargez lien sur ligne 122!!!! For those who are more advanced: gitlab.constantvzw.org/algolit
- Datastructures https://docs.python.org/3/tutoriapl/datastructures.html ‘0_datastructures’: example scripts using different datastructures
- Creating recipes ‘1_oulipo_scripts’: example scripts playing with recipes & text input
- Toolbox ‘2_toolbox’: handy scripts for cleaning up texts, counting frequencies of words, often used for text analysis
- Wordnet ‘3_using_wordnet’: example script for French use of Wordnet
- Running scripts in browser ‘4_cgi_webs_reduction’: interface with reduction filters, developed for a workshop in framework of Transmediale 2017: https://machineresearch.wordpress.com/about/
- Creating pdfs from scripts ‘5_books-oulipo-series’: read the instructions examples online: http://site.sarahgarcin.com/oulipo-series/catalogue.php http://site.sarahgarcin.com/oulipo-series/perec.php
*OLA_Oulipo_workshop.zip https://g-u-i.me/owncloud/index.php/s/Ye5zxwAWPWcxoX6
https://g-u-i.me/owncloud/index.php/s/R3MEqmgcGvfTVHk http://www.algolit.net/oulipo/0_datastructures/
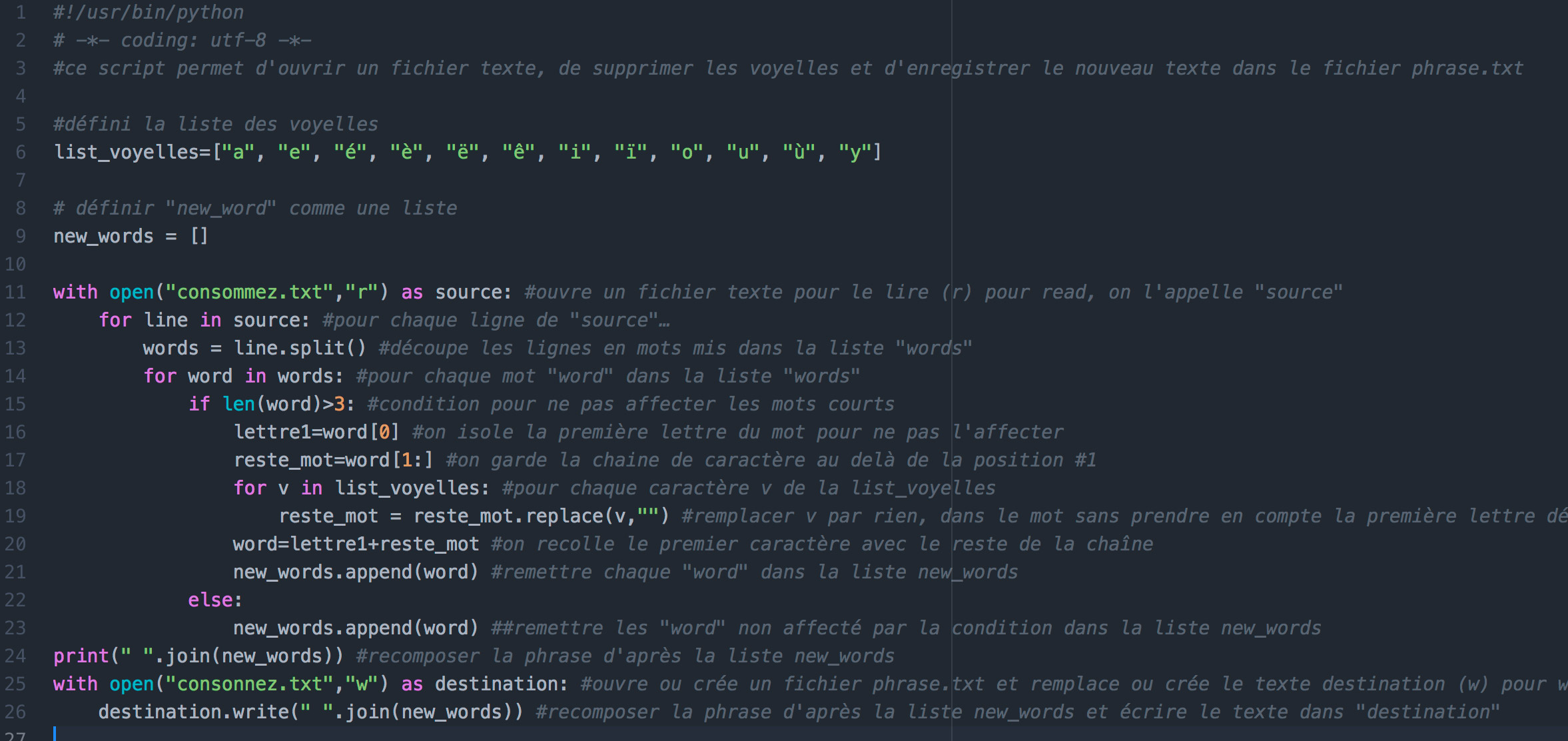
ajouter en haut de chaque script #!/usr/bin/python # -- coding: utf-8 --
*Armelle Caron http://bigthink.com/strange-maps/502-hung-out-to-dry-a-taxonomy-of-city-blocks
*En Française dans la texte Un projet de Cécile Babiole et Anne Laforet En française dans la texte est un projet artistique et critique sur le thème : “langue française et genre”. Il s’agit de contrer le sexisme inscrit au cœur de la langue française, de sa grammaire et de son usage puisque “le masculin l’emporte toujours sur le féminin”. Le projet consiste à traduire “en française” c’est-à-dire entièrement au féminin, des textes provenant de différents horizons, grâce à des algorithmes complétés par des opérations manuelles. C’est ainsi que les traductions perturbent sensiblement les messages originaux. Le processus de traduction fait l’objet de performances, d’installations et d’éditions. http://enfrancaisedanslatexte.fr/
Stanford NER is a Java implementation of a Named Entity Recognizer. Named Entity Recognition (NER) labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names. It comes with well-engineered feature extractors for Named Entity Recognition, and many options for defining feature extractors. Included with the download are good named entity recognizers for English, particularly for the 3 classes (PERSON, ORGANIZATION, LOCATION), and we also make available on this page various other models for different languages and circumstances, including models trained on just the CoNLL 2003 English training data. *https://nlp.stanford.edu/software/CRF-NER.shtml
*Prolex Le projet Prolex, piloté par le Laboratoire d’informatique (LI) de l’université François-Rabelais de Tours, a pour but de fournir, à la communauté du traitement automatique des langues (Tal), des connaissances sur les noms propres, qui constituent, à eux seuls, 10% des textes journalistiques. Ceci par la création d’une plate-forme technologique comprenant un dictionnaire électronique relationnel multilingue de noms propres (Prolexbase), des systèmes d’identification des noms propres et de leurs dérivés, des grammaires locales, etc. http://www.cnrtl.fr/lexiques/prolex/
*Un correcteur orthographique en 21 lignes de Python blog post sur le principe de fonctionnement d’unn correcteur othographique http://blog.proxteam.eu/2013/10/un-correcteur-orthographique-en-21.html
*GNU Aspell http://aspell.net/ ftp://ftp.gnu.org/gnu/aspell/dict/0index.html https://pypi.python.org/pypi/aspell-python-py3/1.13
http://www.lexique.org/ base de données qui fournit pour 135 000 mots du français faite par l’université de Savoie
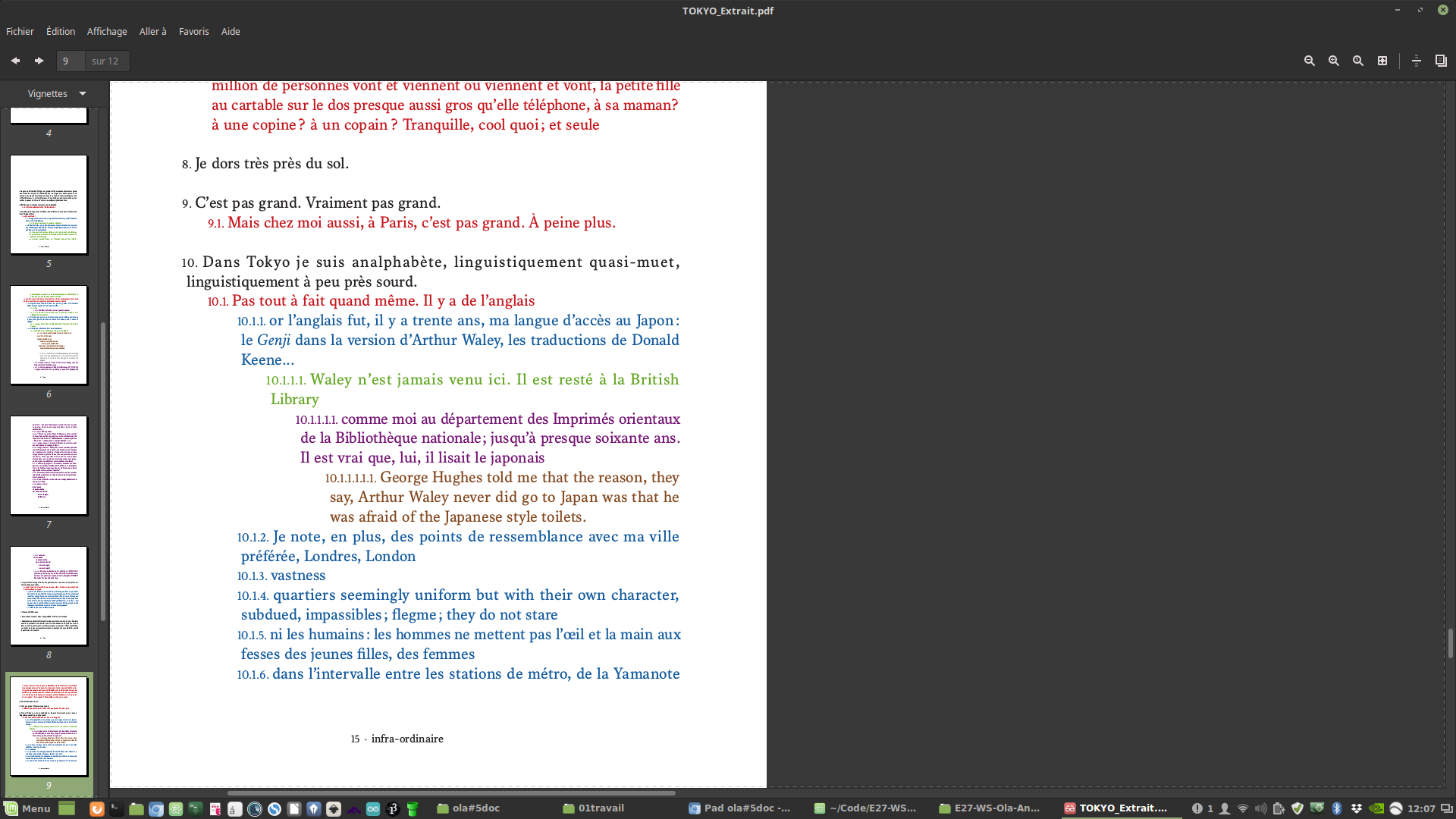
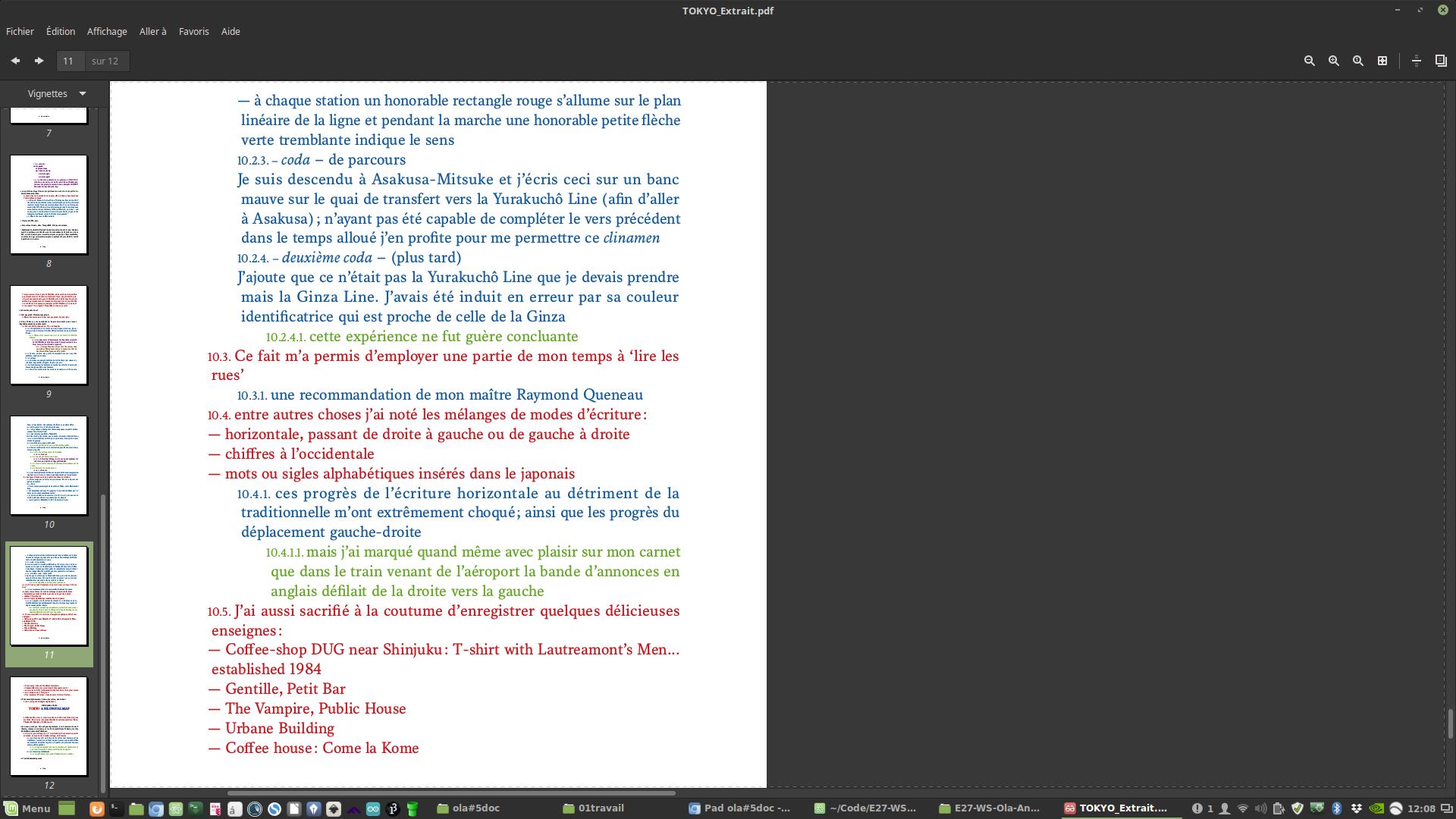
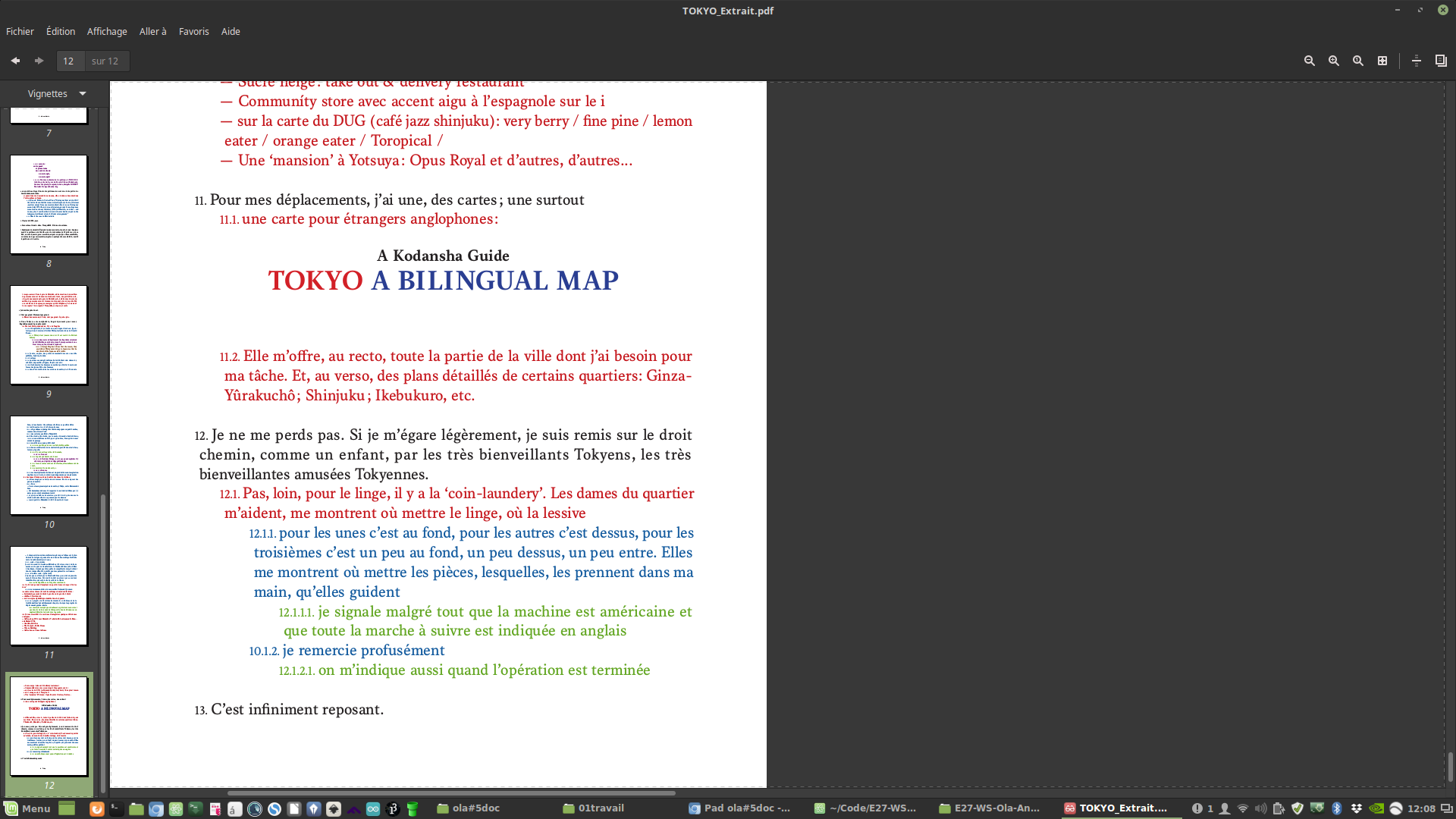
Jacques Roubaud https://issuu.com/letripode/docs/tokyo_extrait http://oulipo.net/fr/oulipiens/jr
Pyenv Pour utiliser plusieurs versions de Python sur le même système : http://leetschau.github.io/blog/2014/08/06/144020/
Livre sur Python : Apprendre à programmer avec Python 3 de Gérard Swinnen (gratuit : http://inforef.be/swi/download/apprendre_python3_5.pdf)
*librairies python pour le texte
Patterns : https://www.clips.uantwerpen.be/pattern
*installer pattern (mint linux, distribution basée sur Ubuntu)
- installer pip : sudo apt-get install python-pip
- installer setup tools : sudo pip install setuptools
- installer pattern : sudo pip install pattern
#coding:utf-8
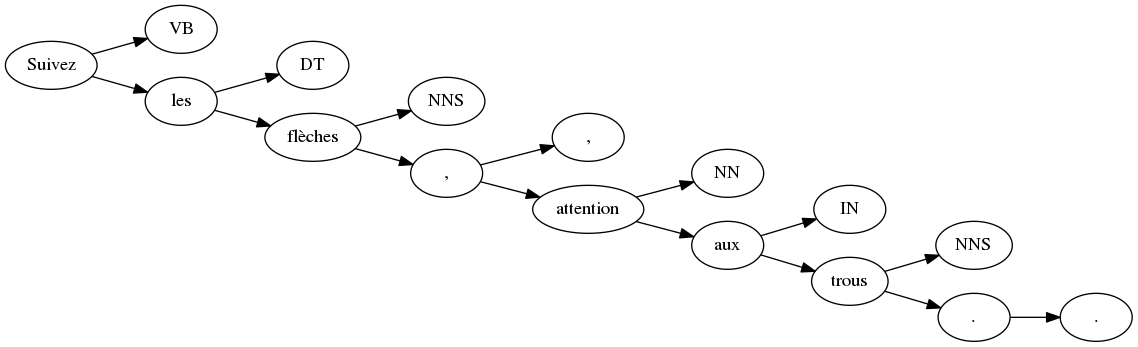
Pattern list des abbréviations Parts of Speech: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
*partage de fichiers rapide pour les présentations :
https://volafile.org/r/f4q1z59g
*Ethica http://ethica-spinoza.net/fr/inline
*Uttiliser espeak
télécharger espeak via le gestionnaire de paquet apt-get install espeak ou par sur le site officiel (http://espeak.sourceforge.net/download.html)
uttilisation la plus simple : espeak “Hello world”
connaitre les voix disponnible en fançais espeak - voices=fr
uttiliser une des voix disponnibles espeak -v french “Salut monde”
faire lire à espeak la sortie de mon proggrame python python mon_programme.py | espeak
faire lire à espeak la sortie de mon proggrame python et enregistrer le résultat dans un fichier audio python mon_programme.py | espeak -w test.wav
pour des meilleures voix francaise chercher du côté de mbrola